How to Create an Effective Enterprise Data Strategy: Part 1
A Guide for how we develop a Scalable, Secure, and Efficient Data Strategy for our Modern Businesses

TLDR
Introduction
Overview of the importance of Data management in enterprises
Data management is vital for enterprises as it
Ensures that data is accurate, accessible, and secure, which is essential for informed decision-making.
Helps organizations streamline operations, improve efficiency, and enhance customer experiences by providing reliable data insights.
Supports compliance with regulatory requirements and reduces the risk of data breaches by implementing robust security measures.
Drives innovation and competitive advantage by enabling advanced analytics and data-driven strategies.
Key Features of an Effective Data Sharing Solution in Enterprises
Every organization needs a powerful data sharing solution that is
Powerful enough to share data of any size.
Agnostic enough to be used by any tool or programming language.
Scalable enough to support all users all the time.
Secure enough to ensure the right people have access to the right data.
Achieving this goal will truly make the solution great. Users will have enough confidence, eventually leading to a good adoption rate.
What, Where, How problem statements, solving each unit individually. By combining them, we eventually construct the overall solution.Robust Data Platform Architecture
Here, we'll cover the key architecture choices we made to build a strong data platform that meets all business needs.
Data storage strategy
The What
These are extremely important steps. You have to make the right choice at the beginning, because if you make the wrong choice then data migration will be a difficult task. Usually, the options to choose from or either Data Warehouse or Data Lakehouse.
We choose to go with Data Lakehouse for the following reasons:
A Data Lakehouse provides a centralized location to store all types of data.
It supports not only structured data like tables but also unstructured data such as images, videos, and binaries, as it’s built on top of a
Data lake.Its modular & open design is highly advantageous. By separating storage from data processing, it allows for the use of various tools to read, write, and process data efficiently.
The Where
Out of all the Data Lakehouse out there, we choose Databricks Lakehouse for the following reasons:
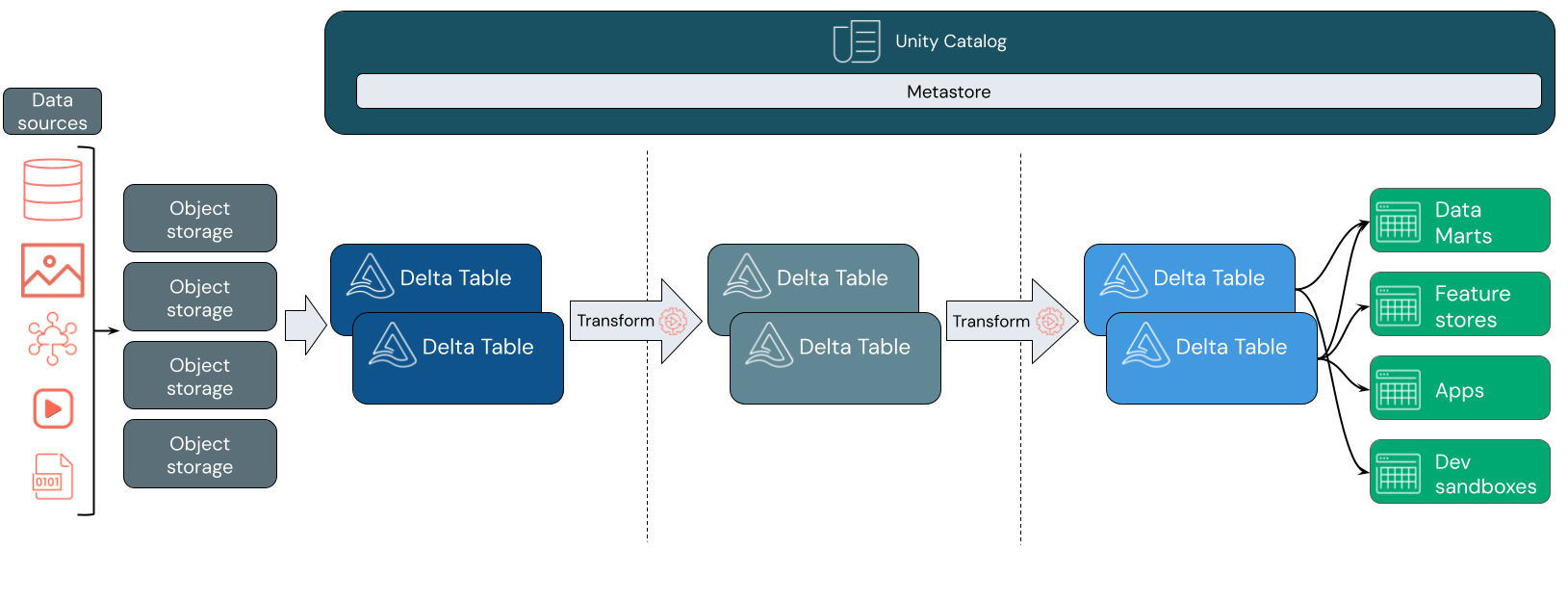
Databricks Lakehouse supports
cloud storage objectsfor data storage. We already useAzure ADLS gen2, which is natively supported by Databricks Lakehouse.It utilizes
Apache Spark(PySpark+Spark SQL) for processing and transforming data. While many tools can handlebig data, none match the capabilities ofApache Spark.It employs the
Delta Lakeformat to store data in tables. Delta Lake introduces ACID properties, a key feature that previously deterred users from moving away fromData WarehousestoData lakes, which paved the way forData Lakehouse.
The How
There are many well-defined strategies used in storing data. Since we are using the Databricks Lakehouse platform, we went ahead with Databricks’ Medallion Architecture
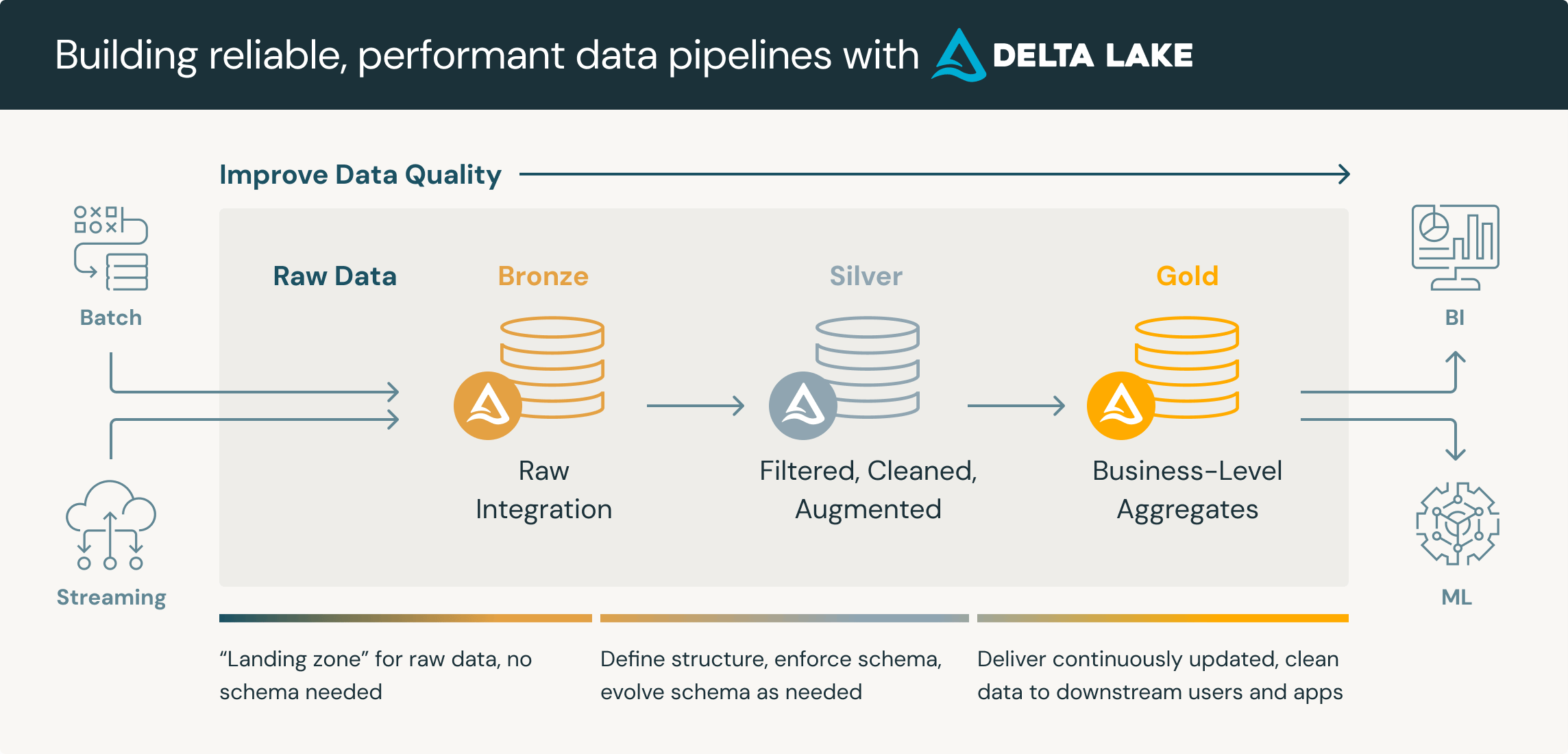
Adopting the Medallion architecture has allowed us to enhance data quality by organizing data into three distinct namespaces, each serving a specific purpose, ensuring they do not interfere with one another.
The Medallion architecture also improves our ability to meet business needs, as the gold layer is specifically designed to cater to those requirements.
It also provides a unified data management ability to ease engineering efforts.
Facilitate Data Sharing & Consumption
A robust Enterprise data strategy must have equally robust data sharing & consumption capabilities.
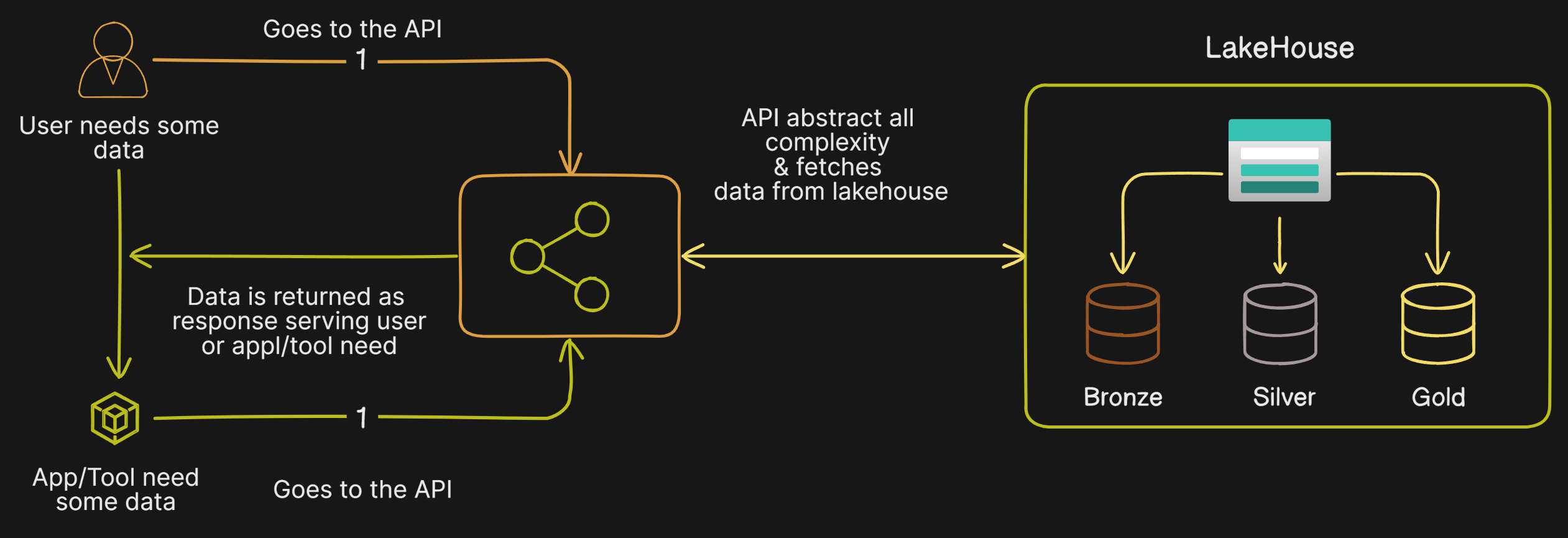
The What
Data Sharing- The goal is to make data accessible throughout the organization.Data Consumption- The goal is to make reading and writing data simple and convenient for authorized users and applications by abstracting all the complexity.
The Where
Both layers - Data Sharing & Consumption - should act as middleware between the user/tool and the
Lakehouse.We tried multiple options for hosting it but eventually settled on
Kubernetes. We were already using it for other products too. However, hosting the application should be purely based on your requirements (and it's a little out of scope for this article too).
The How
We took inspiration from how two independent services usually communicate & majorly the answer is
APIs.In 2024, we had two options to choose from either
REST APIorGraphQL.We selected
REST APIbecauseGraphQLstill has limited support across many tools. Almost all tools and programming languages support REST API, making it universally compatible.
Security Architecture
I cannot stress enough that Security Architecture is as important as other architectures like application, scaling, etc. Treating security as a secondary citizen or an afterthought will come back to haunt you later.
To satisfy all our security needs, we broke down the architecture into parts - Data Security & Access control
Data Security
Effective data security measures are crucial for any organization.
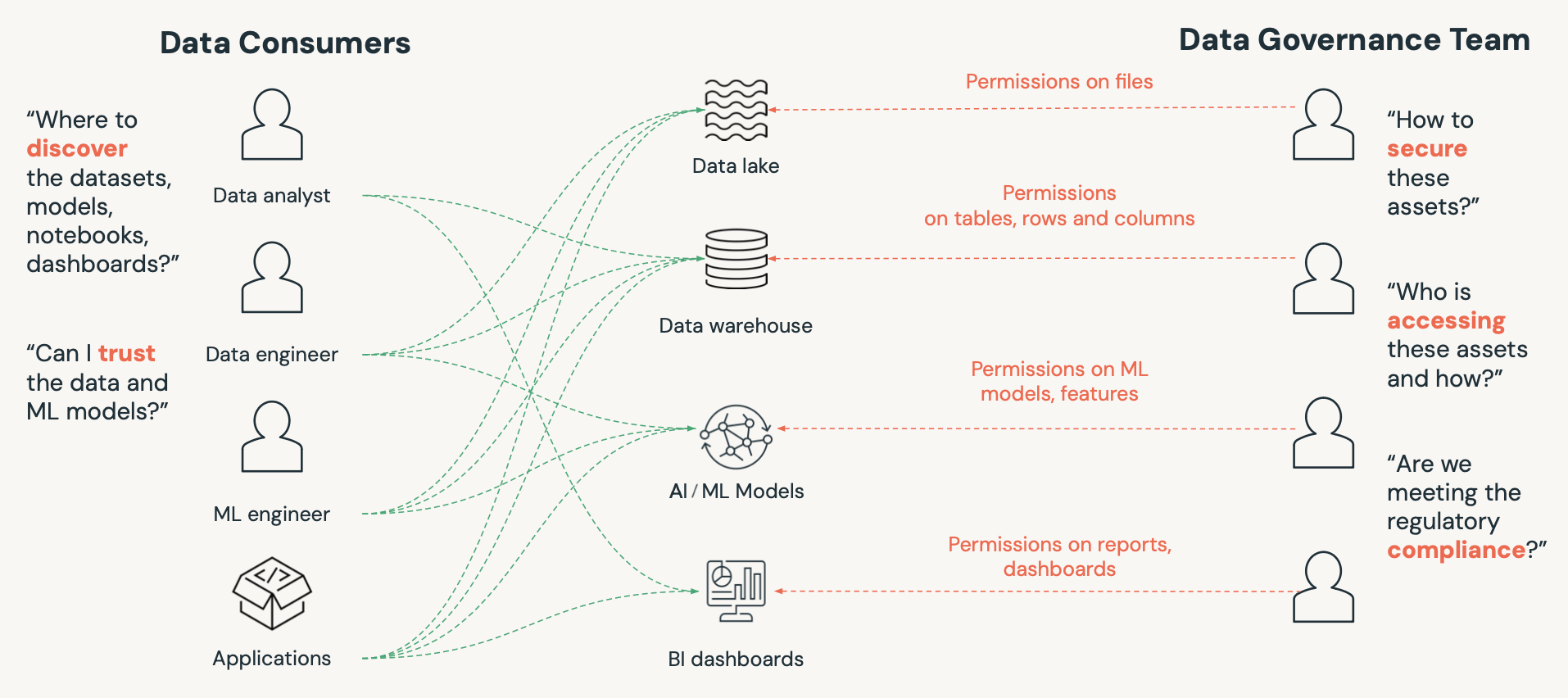
The What
The goal is to have the ability to store data securely
The goal is to follow any region specific data localization or compliance policies.
The goal is to restrict unauthorized use of sensitive data.
The Where
Databricks Lakehouse lets us save table data externally to cloud storage. We use this feature to store all our tables in
Azure ADLS Gen2. This ensures our data is securely stored.Azure allows us to select the location of our storage account. So we use a multi-region storage account strategy to meet data localization policies.
The How
Since we are using
Azure ADLS Gen2, we get multi-layered security like authentication, access control, network isolation, data protection, advanced threat protection, and auditing.The most crucial is played by
Databricks Unity Catalog. It goes hand in hand with the multi-region storage account strategy. Here is how we did itStep 1: Configure external locations and storage credentials - External locations are defined as a path to cloud storage, combined with a storage credential that can be used to access that location. - A storage credential encapsulates a long-term cloud credential that provides access to cloud storage. Step 2: Configure region specific Unity Catalog - From above step, now we use region specific storage account storage credentials to create it's dedicated unity catalog. - Once we have the unity catalog created, we can use Spark (SQL or Pyspark) to process the data. Step 3: Managing all catalogs - This is where Databricks really shines. we can have all different region based unity catalog under same workspace. - This way we can run our spark jobs or ETL pipelines, process the data save it back to appropriate location. - This way we comply with all policies.
Access Control
The Security architecture isn't just about external protection or following policies; we also need to make sure it's secure on the inside too. This can be done using the Access Control principals.
The What
The goal is to ensure that only authorized users can access specific data, preventing unauthorized access and potential data breaches.
The goal is to control who can view or modify data, access control helps maintain the integrity of the data, ensuring that it remains accurate and reliable.
The goal is to provide a clear audit trail of who accessed or modified data, which is essential for accountability and transparency.
The Where
Since we are using
Databricks Lakehousewith External location, we have to implement two Access Control strategies.Governance with
Databricks Unity Catalog:It allows us
GRANTfine grain control like select, read, write, etc to the various objects like table, view, volume, model, etc.We use
User Groups principalinstead of directuser principlesfor granting any access.
Access Control in
Azure ADLS Gen2:All the files associated with tables, views, and models are stored in cloud storage. We made sure that any group will not have higher permission than they have over Databricks Unity Catalog.
To keep it simple we usually don’t provide
writeaccess to storage accounts associated with higher environments to users. Everything is controlled by the Access Control policy in Databricks.
The How
Databricks offers a highly adaptable governance policy, which we leverage extensively.
We implement a
Zero Trust Policyin combination withRole-Based Access Control.For each
Schema, we have established roles such asreader,writer, andowner. Depending on the specific use case,Groupsare assigned these roles. Subsequently, theUseris added to the appropriateGroup.When a
Userno longer requires access, they are removed from the group, eliminating the need for frequent modifications to the grants.The
Service Principalis crucial, especially in the production environment. We only use it to execute jobs.
Conclusion
Creating an effective enterprise data strategy is essential for harnessing the full potential of data. Focus on robust data management, secure data sharing, and comprehensive security architecture.
Implement a well-thought-out data platform architecture, like the Databricks Lakehouse with Medallion Architecture, for efficient data storage and processing.
Facilitate seamless data sharing and consumption through universally compatible APIs for easy access by authorized users.
Adopting these strategies helps drive innovation, gain a competitive edge, and make informed decisions based on reliable data insights.