MLOps: The Upcoming Shining Star
The right path to building a full-stack machine learning system. MLOps is the new emerging practice to streamline managing the ML lifecycle.

Why in the world shouldn’t I prioritize building ‘The Perfect Model’?
Before reading further, I would suggest you read this paper. It discusses all of the related problems in detail.
The major hurdles that generally arise while developing ML apps are:
Current Challenges of Productionizing Machine learning models
Complex Models Abstraction Boundaries
Traditional software engineering practice has shown that strong abstraction boundaries using encapsulation and modular design help create maintainable code in which it is easy to make isolated changes and improvements. But in the case of ML, enforcing strict action becomes difficult because of its dependency on external data.
Data Dependency
Data Dependencies Cost More than Code Dependencies
Feeding the data to training and steps done at the evaluation stage in the data scientist sandbox can dramatically vary in real-world scenarios. Depending on the use case data changes with time and lack of regularity cause poor performance of ML models.
Simple to complex pipelines
Training a simple model and putting it into inference and generating prediction is a simple way of getting business insights, this is not sufficient. In real-world cases, regularity is needed and time models need to be retrained on new data which will be fetched from the data lake. So there are going to be many models & with human approval to decide which model to choose for production. In the Federated pipeline, it becomes even more challenging to maintain.
Configuration Debt
Any large system has a wide range of configurable options, including which features are used, how data is selected, a wide variety of algorithm-specific learning settings, potential pre or post-processing, verification methods, etc. In a mature system that is being actively developed, the number of lines of configuration can far exceed the number of lines of the traditional code. Each configuration line has the potential for mistakes.
Reproducibility Debt
It is important that we can re-run experiments and get similar results, but designing real-world systems to allow for strict reproducibility is a task made difficult by randomized algorithms, non-determinism inherent in parallel learning, reliance on initial conditions, and interactions with the external world.
Production ML Risk
There is always the risk of ML models not doing and needs continuous monitoring and evaluation if they are performing within expected bound. On live data metrics like Accuracy, Precision, recall, etc. cannot be used as live data does not have labels.
Process and Collaboration
In production, ML requires multiple abilities to handle production grades ML systems like data scientists, data engineers, business analysts, and operations. Different teams will focus on various outcomes. The Data scientist will focus on improving the accuracy and detecting data deviations, the business analyst wants to enhance KPI’s, operations team wish to see uptime and resources. Unlike the Data scientist sandbox, the production environment has many objects like models, algorithms, pipelines, etc. that are difficult to handle and versioning of them is yet another issue, object storage is needed to store the ML models, and source control repository is not the best option.
What is MLOps?
MLOps establishes a culture and environment where ML technologies can generate business benefits by optimizing the ML lifecycle to automate and scale ML initiatives and optimized business return of ML in production. MLOps have mix capabilities of Data scientists and services
MLOps enables collaboration across diverse users (such as Data Scientists, Data Engineers, Business Analysts and ITOps) on ML operations and enables a data-driven continuous optimization of ML operations’ impact or ROI (Return on Investment) to business applications.
Why MLOps?
It is pretty clear from the above content that what is the need for ‘MLOps’ and what lead to the rise of this hybrid approach in the modern era of Artificial Intelligence. Now moving forward from ‘What’ to ‘Why.’ Let us give some light on the reasons which led to the use of MLOps in the first place.
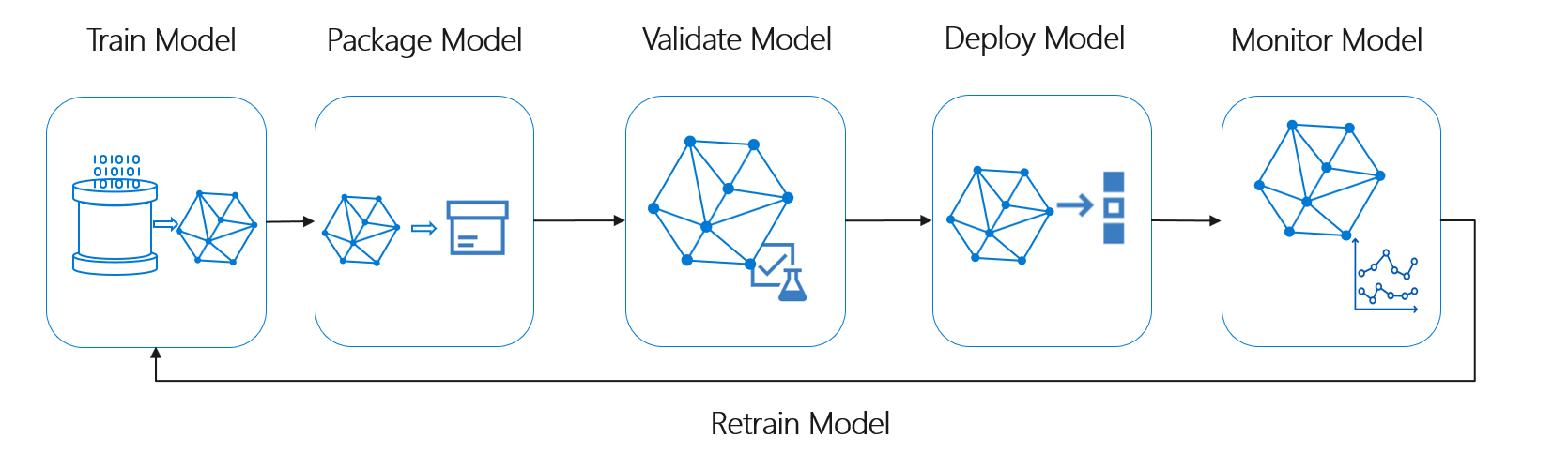
Orchestration of multiple pipelines
The development of machine learning models is not a single code file task. Instead, it involves the combination of the different pipelines which have their roles to perform.
Pipelines for the primary process such as pre-processing, feature engineering model training and model inference, etc. involved in the big picture of the development of the machine learning model.
MLOps play an essential role in the simple orchestration of these multiple pipelines to ensure the updating of the model automatically.
Manage Full Life Cycle of MLOps
The life cycle of a Machine learning model consists of different sub-parts which should be considered as a software entity individually.
These sub-parts have their own need for management and maintenance, which often handled by DevOps, but it is challenging to manage them using traditional DevOps methods.
MLOps is the newly emerged technique which includes a combination of people, process, and technology that give an edge to swiftly and safely optimize and to deploy machine learning models.
Scale ML Applications
As it is said earlier in the topic, the development of models is not an issue to be worried about, and the real problem lies in the management of the models at scale.
The management of the thousands of models at once is a very cumbersome and challenging task which test the performance of the models at scale.
With the use of MLOps, it naturally scales the manage thousands of pipelines of models in production.
Maintain ML Health
To maintain ML health after the deployment of ML models is the most critical part of the post-process. It is vital so that ML models can be operated and managed flawlessly.
MLOps provide the latest ML health methods by enabling the detection of different drifts (model drift, data drift) in an automated way.
It can provide the ability to use the latest edge cutting algorithms in the system to detect these drift so that these drifts can be avoided much before they will start to affect ML health.
Continuous Integration and Deployment
Continuous Integration and Deployment is one of the whole sole purposes, which led to the use of DevOps in any software product development procedures.
But due to the scale of the operability of ML models, it is difficult to use the same methods of continuous integration and deployment, which are used for other software products.
MLOps can provide the hands to use different dedicated tools and techniques which are specialized to ensure the continuous integration and deployment services in the field of ML models.
Model Governance
Under Model Governance, MLOps can provide rich model performance data by applying to monitor the attributes on a massive scale.
It can also provide the ability to take snapshots of the pipelines for analyzing critical moments.
Also, the logging facilities and audit trails under MLOps can be used for reporting and continuity of compliance.
How is MLOps different from DevOps?
Data/model versioning != code versioning
Model reuse entirely has different case than software reuse, as models need tuning based on scenarios and data.
Fine-tuning is needed when to reuse a model. Transfer learning on it, and it leads to a training pipeline.
Retraining ability requires on-demand as the models decay over time.
Let’s talk about Full Stack Machine Learning Development, shall we?
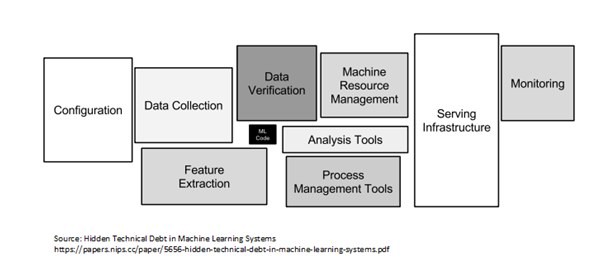
As you may already have got the gist, but let’s talk about in some detail.
Developing a ML system is just not developing a model, but it is much more. Configuration, Data collection, Deployment, Serving, etc (as shown in dig above).
So for Rapid but safe, High confidence but generic, Development-friendly but also production-friendly, we need to replicate all the best practices of Software Development in ML development.
As DevOps is helping Software Development into Full stack development, so does MLOps will help ML development to Full Stack ML development.
Embracing Mlops into ML Development will always ensure the confidence in ML System.
I will be publishing a new series on building the right Full-stack ML system. I will keep you posted… :)