Working with Hugging Face Transformers and TF 2.0

Models based on Transformers are the current sensation of the world of NLP. Hugging Face’s Transformers library provides all SOTA models (like BERT, GPT2, RoBERTa, etc) to be used with TF 2.0 and this blog aims to show its interface and APIs

0. Disclaimer
I am assuming that you are aware of Transformers and its attention mechanism. The primary aim of this blog is to show how to use Hugging Face’s transformer library with TF 2.0, i.e. it will be a more code-focused blog.
1. Introduction
Hugging Face initially supported only PyTorch, but now TF 2.0 is also well supported. You can find a good number of quality tutorials for using the transformer library with PyTorch, but the same is not true with TF 2.0 (primary motivation for this blog).
To use BERT or even AlBERT is quite easy and the standard process in TF 2.0 courtesy to tensorflow_hub, but the same is not the case with GPT2, RoBERTa, DistilBERT, etc. Here comes Hugging Face’s transformer library to rescue. They provide intuitive APIs to build a custom model from scratch or fine-tune a pre-trained model for a wide list of transformer-based models.
It supports a wide range of NLP application like Text classification, Question-Answer system, Text summarization, Token classification, etc. Head over to their Docs for more detail.
This tutorial will be based on a Multi-Label Text classification of Kaggle’s Toxic Comment Classification Challenge.
Following is a general pipeline for any transformer model:
Tokenizer definition →Tokenization of Documents →Model Definition →Model Training →Inference
Let us now go over them one by one, I will also try to cover multiple possible use cases.
2. HuggingFace transformer General Pipeline
2.1 Tokenizer Definition
Every transformer based model has a unique tokenization technique, unique use of special tokens. The transformer library takes care of this for us. It supports tokenization for every model which is associated with it.
from transformers import DistilBertTokenizer, RobertaTokenizer,
distil_bert = 'distilbert-base-uncased' # Pick any desired pre-trained model
roberta = 'roberta-base-uncase'
# Defining DistilBERT tokonizer
tokenizer = DistilBertTokenizer.from_pretrained(distil_bert, do_lower_case=True, add_special_tokens=True,
max_length=128, pad_to_max_length=True)
# Defining RoBERTa tokinizer
tokenizer = RobertaTokenizer.from_pretrained(roberta, do_lower_case=True, add_special_tokens=True,
max_length=128, pad_to_max_length=True)
- Every transformer model has a similar token definition API
- Here I am using a tokenizer from a Pretrained model.
Here,
add_special_tokens: Is used to add special character like <cls>, <sep>,<unk>, etc w.r.t Pretrained model in use. It should be always kept True
max_length: Max length of any sentence to tokenize, it's a hyperparameter. (originally BERT has 512 max length)
pad_to_max_length: perform padding operation.
2.2 Tokenization of Documents
The next step is now to perform tokenization on documents. It can be performed either by encode() or encode_plus() method.
def tokenize(sentences, tokenizer):
input_ids, input_masks, input_segments = [],[],[]
for sentence in tqdm(sentences):
inputs = tokenizer.encode_plus(sentence, add_special_tokens=True, max_length=128, pad_to_max_length=True,
return_attention_mask=True, return_token_type_ids=True)
input_ids.append(inputs['input_ids'])
input_masks.append(inputs['attention_mask'])
input_segments.append(inputs['token_type_ids'])
return np.asarray(input_ids, dtype='int32'), np.asarray(input_masks, dtype='int32'), np.asarray(input_segments, dtype='int32')
- Any transformer model generally needs three input:
- input ids: word id associated with their vocabulary
- attention mask: Which id must be paid attention to; 1=pay attention. In simple terms, it tells the model which are original words and which are padded words or special tokens
- token type id: It's associated with model consuming multiply sentence like Question-Answer model. It tells the model about the sequence of the sentences.
- Though it is not compulsory to provide all these three ids and only input ids will also do, but attention mask helps the model to focus on only valid words. So at least for the classification task both these should be provided.
2.3 Training and Fine-tuning
Now comes the most crucial part, the ‘Training’. The method that I will discuss is by no means ‘the only possible way’ to train. Though after a lot of experimenting I found this method to be most workable. I will discuss three possible ways to train the model:
Use Pretrained model directly as a classifier
Transformer model to extract embedding and use it as input to another classifier.
Fine-tuning a Pretrained transformer model on custom config and dataset.
2.3.1 Use Pretrained model directly as a classifier
This is the simplest but also with the least application. Hugging Face’s transformers library provide some models with sequence classification ability. These model have two heads, one is a pre-trained model architecture as the base & a classifier as the top head.
Tokenizer definition →Tokenization of Documents →Model Definition
from transformers import TFDistilBertForSequenceClassification, DistilBertConfig
import tensorflow as tf
distil_bert = 'distilbert-base-uncased'
config = DistilBertConfig(num_labels=6)
config.output_hidden_states = False
transformer_model = TFDistilBertForSequenceClassification.from_pretrained(distil_bert, config = config)[0]
input_ids = tf.keras.layers.Input(shape=(128,), name='input_token', dtype='int32')
input_masks_ids = tf.keras.layers.Input(shape=(128,), name='masked_token', dtype='int32')
X = transformer_model(input_ids, input_masks_ids)
model = tf.keras.Model(inputs=[input_ids, input_masks_ids], outputs = X)
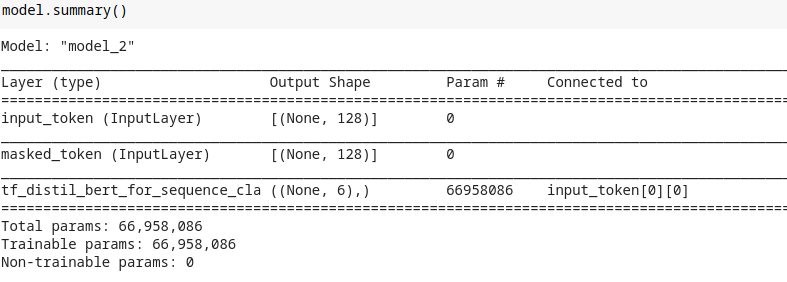 Summary of Pretrained model directly as a classifier
Summary of Pretrained model directly as a classifier
- Note: Models which are SequenceClassification are only applicable here.
- Defining the proper config is crucial here. As you can see on line 6, I am defining the config. ‘num_labels’ is the number of classes to use when the model is a classification model. It also supports a variety of configs so go ahead & see their docs.
Some key things to note here are:
- Here only weights of the pre-trained model can be updated, but updating them is not a good idea as it will defeat the purpose of transfer learning. So, actually there is nothing here to update. This is the reason I least prefer this.
- It is also the least customizable.
- A hack you can try is using num_labels with much higher no and finally adding a dense layer at the end which can be trained.
# Hack
config = DistilBertConfig(num_labels=64)
config.output_hidden_states = False
transformer_model=TFDistilBertForSequenceClassification.from_pretrained(distil_bert, config = config)
input_ids = tf.keras.layers.Input(shape=(128,), name='input_token', dtype='int32')
input_masks_ids = tf.keras.layers.Input(shape=(128,), name='masked_token', dtype='int32')
X = transformer_model(input_ids, input_masks_ids)[0]
X = tf.keras.layers.Dropout(0.2)(X)
X = tf.keras.layers.Dense(6, activation='softmax')
model = tf.keras.Model(inputs=[input_ids, input_masks_ids], outputs = X)
for layer in model.layer[:2]:
layer.trainable = False
2.3.2 Transformer model to extract embedding and use it as input to another classifier
This approach needs two-level or two separate models. We use any transformer model to extract word embedding & then use this word embedding as input to any classifier (eg Logistic classifier, Random forest, Neural nets, etc).
I would suggest you read this article by Jay Alammar which discusses this approach with great detail and clarity.
As this blog is all about neural nets, let me explain this approach with NN.
distil_bert = 'distilbert-base-uncased'
config = DistilBertConfig(dropout=0.2, attention_dropout=0.2)
config.output_hidden_states = False
transformer_model = TFDistilBertModel.from_pretrained(distil_bert, config = config)
input_ids_in = tf.keras.layers.Input(shape=(128,), name='input_token', dtype='int32')
input_masks_in = tf.keras.layers.Input(shape=(128,), name='masked_token', dtype='int32')
embedding_layer = transformer_model(input_ids_in, attention_mask=input_masks_in)[0]
cls_token = embedding_layer[:,0,:]
X = tf.keras.layers.BatchNormalization()(cls_token)
X = tf.keras.layers.Dense(192, activation='relu')(X)
X = tf.keras.layers.Dropout(0.2)(X)
X = tf.keras.layers.Dense(6, activation='softmax')(X)
model = tf.keras.Model(inputs=[input_ids_in, input_masks_in], outputs = X)
for layer in model.layers[:3]:
layer.trainable = False
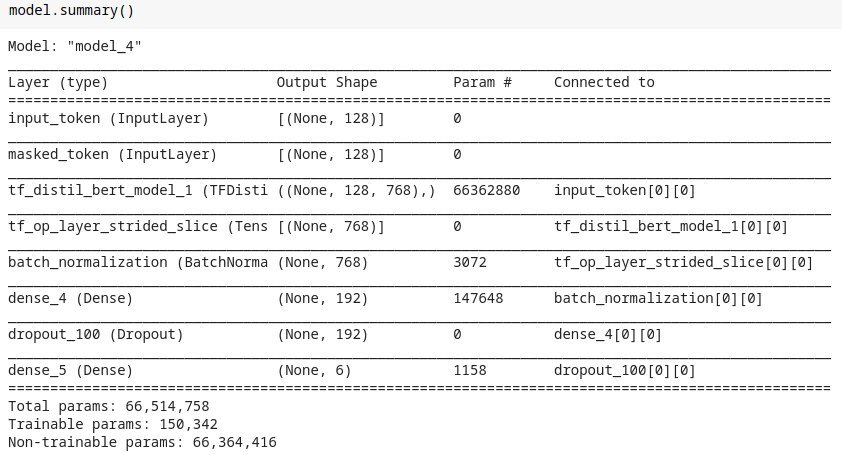 Model Summary
Model Summary
- Line #11 is key here. We are only interested in <cls> or classification token of the model which can be extracted using the slice operation. Now we have 2D data and build the network as one desired.
- This approach works generally better every time compared to 2.3.1 approach. But it also has some drawbacks, like:
- It is not so suitable for production, as you must be using transformer model as a just feature extractor and so you have to now maintain two models, as your classifier head is different (like XGBoost or Catboast ).
- While converting 3D data to 2D we may miss on valuable info.
The transformers library provide a great utility if you want to just extract word embedding.
import numpy as np
from transformers import AutoTokenizer, pipeline, TFDistilBertModel
model = TFDistilBertModel.from_pretrained('distilbert-base-uncased')
tokenizer = AutoTokenizer.from_pretrained('distilbert-base-uncased')
pipe = pipeline('feature-extraction', model=model,
tokenizer=tokenizer)
features = pipe('any text data or list of text data',
pad_to_max_length=True)
features = np.squeeze(features)
features = features[:,0,:]
2.3.3 Fine-tuning a Pretrained transformer model**
This is my favourite approach as here we are making use of the full potential of any transformer model. Here we’ll be using weights of pre-trained transformer model and then fine-tune on our data i.e transfer learning.
distil_bert = 'distilbert-base-uncased'
config = DistilBertConfig(dropout=0.2, attention_dropout=0.2)
config.output_hidden_states = False
transformer_model = TFDistilBertModel.from_pretrained(distil_bert, config = config)
input_ids_in = tf.keras.layers.Input(shape=(128,), name='input_token', dtype='int32')
input_masks_in = tf.keras.layers.Input(shape=(128,), name='masked_token', dtype='int32')
embedding_layer = transformer_model(input_ids_in, attention_mask=input_masks_in)[0]
X = tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(50, return_sequences=True, dropout=0.1, recurrent_dropout=0.1))(embedding_layer)
X = tf.keras.layers.GlobalMaxPool1D()(X)
X = tf.keras.layers.Dense(50, activation='relu')(X)
X = tf.keras.layers.Dropout(0.2)(X)
X = tf.keras.layers.Dense(6, activation='sigmoid')(X)
model = tf.keras.Model(inputs=[input_ids_in, input_masks_in], outputs = X)
for layer in model.layers[:3]:
layer.trainable = False
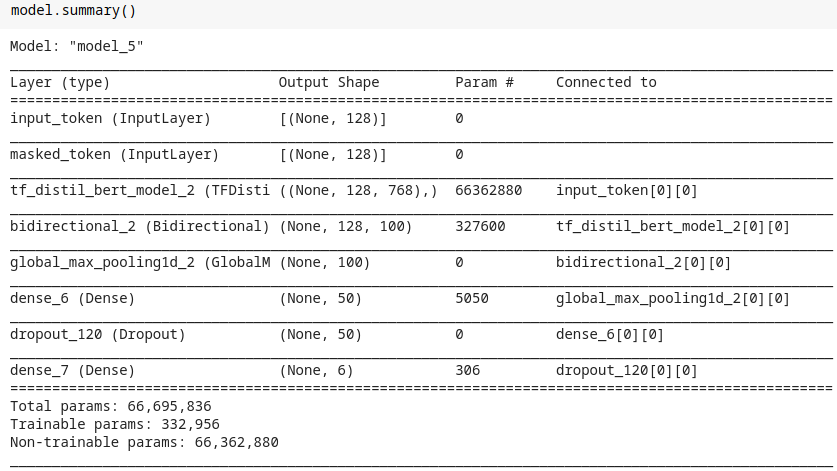
- Look at line #17 as 3D data is generated earlier embedding layer, we can use LSTM to extract great details.
- Next thing is to transform the 3D data into 2D so that we can use a FC layer. You can use any Pooling layer to perform this.
- Also, note on line #18 & #19. We should always freeze the pre-trained weights of the transformer model & never update them and update only the remaining weights.
Some extras
Every approach has two things in common:
config.output_hidden_states=False; as we are training & not interested in output state.
X = transformer_model(…)[0]; this is inline in config.output_hidden_states as we want only the top head.
config is a dictionary. So to see all available configuration, just simply print it.
- Choose the base model carefully as TF 2.0 support is new, so there might be bugs.
2.4 Inference
As the model is based on tf.keras model API, we can use Keras’ same commonly used method of model.predict()
We can even use the transformer library’s pipeline utility (please refer to the example shown in 2.3.2). This utility is quite effective as it unifies tokenization and prediction under one common simple API.
3. End Notes
Hugging Face has really made it quite easy to use any of their models now with tf.keras. It has open wide possibilities.
They have also made it quite easy to use their model in the cross library (from PyTorch to TF or vice versa).
I would suggest visiting their docs, as they have very intuitive & to-the-point docs.